5.1 走近数据分析 知识点题库
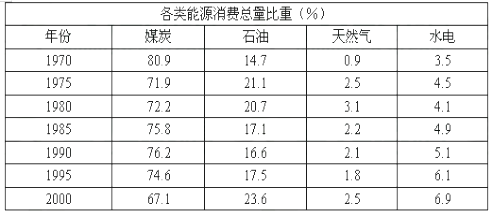
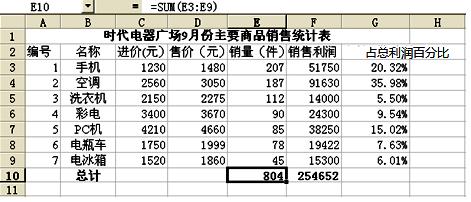
图1
请根据表中数据回答下列问题:
-
(1) 李明在单元格G3使用公式“=F3/$F$10”计算手机占总利润百分比,并对区域G4:G9进行了自动填充,则G9单元格的公式是
-
(2) 李明想将编号这一列数据设计成“001,002,……,007”样式,可每次输入“001,002,……,007”样式后都自动变成了“1,2,……,7”,请给出一种解决方法
-
(3) 根据图2所示,9月份占总利润百分比最大的商品名称是
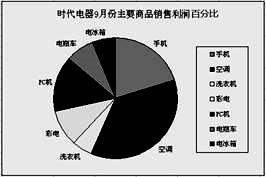
图2
-
(4) 将图2所示的图表以图片形式复制到Word文档中并设置了文字环绕方式,部分界面如图3所示,该图表环绕方式是(单选,填字母:A .嵌入型/B .四周型/C .浮于文字上方/D .紧密型)。

图3
对于上述描述,下列说法不正确的是( )
-
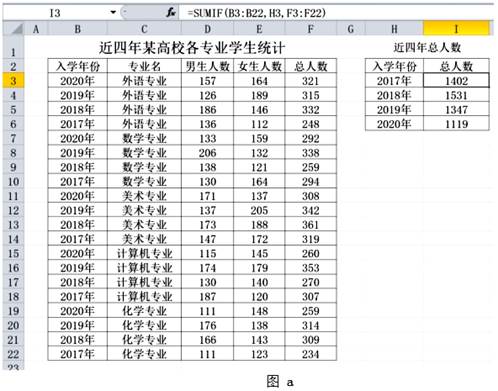
(1) 为计算图a中各个年份入学的总人数,图图已正确计算了单元格I3中的数据。他希望将单元格I3中的公式向下自动填充至单元格I6,从而正确计算出区域I4:I6中的数据,则下列修改I3中的公式方法不可行的是(单选,填字母)。
(提示:SUMIF函数用于统计某个区域中满足条件的单元格数值之和,例=SUMIF(B3:B22,H3,D3:D22),用于统计2017年各专业男生人数之和)
A . =SUMIF($B$3:$B$22,H3,$F$3:$F$22) B . =SUMIF(B$3:B$22,H3,F$3:F$22) C . =SUMIF($B3:$B22,H3,$F3:$F22) -
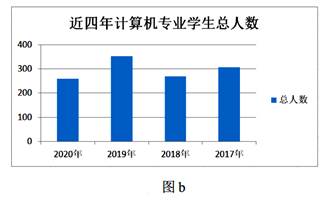
(2) 根据图a中数据制作的图表如图b所示,创建该图表的数据区域是B2,F2,。
-
(3) 在图a所示的工作表中对数据作进一步的数据处理,已知F列中的数据是通过在F3单元格中输入公式“=D3+E3”再向下自动填充至F22计算得到的。则下列说法正确的是 。(多选,填字母)A . 将区域B2:F22中的数据按“总人数”升序排序,则区域I3:I6中的数据不会发生变化 B . 若删除A列,则F列中的单元格将出现错误信息“#REF!” C . 将单元格D15中的数据改为“230”,则图表随之变化 D . 若要筛选出“2020年”总人数最多的专业名称,可以通过“入学年份”为“2020年”,“总人数”为最大1项筛选得到
图a
-
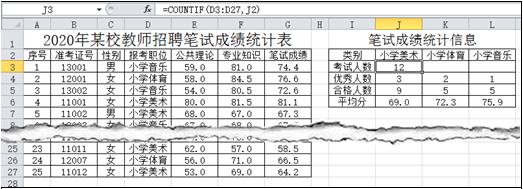
(1) J3单元格中显示的是参加“小学美术”职位的报考人数,利用J3单元格中的公式,对区域K3:L3进行自动填充,则K3单元格中的显示结果是( 单选, 填字母:A . #VALUE! / B . 0 / C . 7)。
(提示:公式“=COUNTIF(D3:D27,J2)”统计区域 D3:D27 中值等于J2的单元格个数,即参加“小学美术”职位的报考人数。)
-
(2) 若要正确计算各个职位报考人数,可先对J3单元格中的公式进行修改,再对区域K3:L3进行自动填充,则J3单元格中的公式应改为。
-
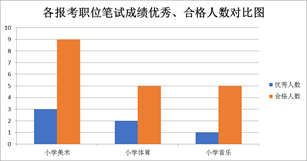
(3) 根据图a中数据制作的图表如图b所示,则制作该图表的数据区域是 。
图b
-
(4) 若对区域A2:G27中的数据以“报考职位”等于“小学音乐”,“笔试成绩”最大一项进行筛选,则筛选后显示的数据一定是报考职位为“小学音乐”中“笔试成绩”的最高分吗?(选填:是/否)。
图a
请回答下列问题:
-
(1) 区域F3:F167的数据是通过公式计算得到的,在F3单元格中输入公式,再使用自动填充功能完成区域F4:F167的计算。
(提示:活动价格(元)=重量(克)×黄金单价(元/克)×活动折扣+加工费(元))
-
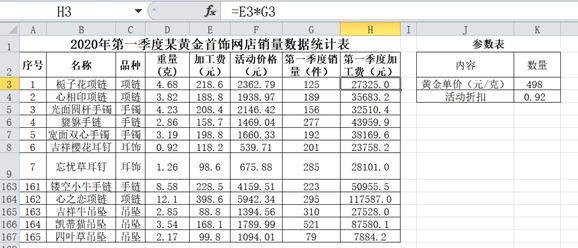
(2) 根据图a中数据制作的图表如图b所示,创建该图表的数据区域是。
图 b
-
(3) 结合图a和图b,下列说法正确的有 _____________(多选,填字母)。A . 若不慎将K列删除,则F3单元格的显示结果是0.00 B . 若将区域E3:E167的单元格格式设置为“数值”并保留 0位小数,“第一季度加工费”列的数值不变 C . 若将区域A165:H167数据以“列D”为关键字进行升序排序,图表会随之改变 D . 若将区域A2:H167以“品种”为手链进行筛选,再以“重量(克)”为关键字降序排序,选取排在最前面的首饰一定是最贵的手链
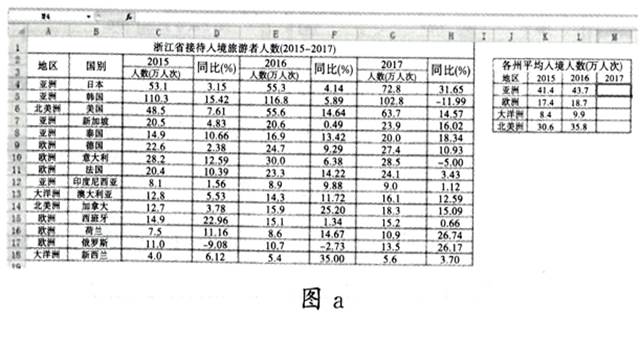
-
(1) 在M4单元格中使用AVERAGEIF函数计算2017年亚洲所有国家的平均入境人数,然后通过自动填充得到M5:M7的公式,则M4单元格中的公式为(提示:AVERAGEIF函数用于对区域中满足条件的单元格求平均。例如:= AVER-AGEIF(A4: A18,J4, E4: E18)表示2016年所有亚洲国家的人境人数平均数)
-
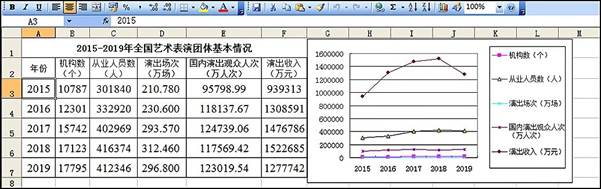
(2) 根据图a中数据制作的图表如图b所示,创建该图表的数据区域是:。
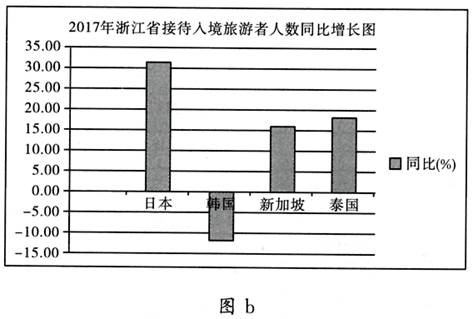
-
(3) 在图a所示的工作表中对数据作进一步操作,下列说法正确的是 (多选:填字母)A . 对表格数据区域A4:H18按“列A”为主要关键字升序排序,则图b中所示的图表不会发生变化。 B . 若要筛选出2016年欧洲入境旅游者人数同比增长最多的国家,可以选择A2:H18区域,以地区为“欧洲”、2016年“同比(%)”为最大1项进行筛选。 C . 若要筛选出2016 年欧洲人境旅游者人数同比增长最多的国家,可以选择A2:H18区域,以地区为“欧洲”进行筛选,再以2016年“同比(%)”为关键字进行降序排序,选取排在最前面的国家。 D . 在正确完成M4:M7计算后,小赵不小心将B列删除,则原M4:M7单元格中的数据不会发生变化。
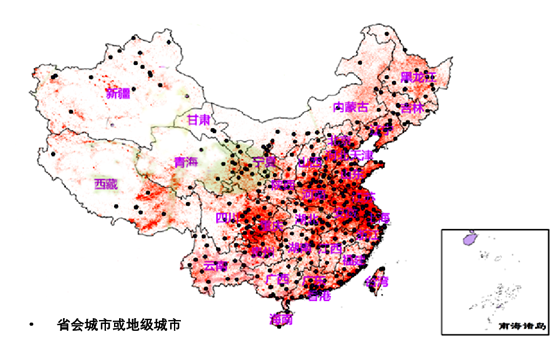
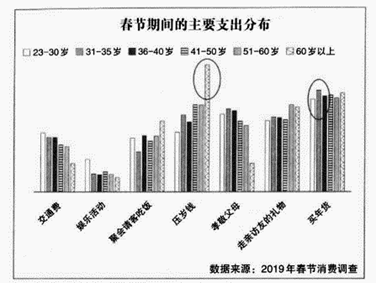
①图片、文字、数值都是数据,数据就是信息
②从图片中可以看到灯光强度增长区域大集中在东部,在一定意义上也代表着东部经济比西部发展得更快
③这张示意图在计算机中是以二进制形式保存的
④灯光强度增强区域示意图的形成得益于大数据的采集和分析

-
(1) 小明对数据进行了整理,下列操作不恰当的是( )(单选,填字母)。A . 发现记录中有6 条重复,对这6 条记录进行了删除 B . 发现记录中有38 处数据项缺失,直接删除相关记录 C . 将某条记录中订单日期“2050-6-9”订正为“2021-6-9” D . 将某条记录中订单日期“2021#3#11”修改为“2021-3-11”
-
(2) 小明发现数据中仍有极少量时间段外的记录混杂其中,利用Python 及pandas 模块进行处理。请回答问题:
① 采用pandas 模块中的(单选:填字母:A .Series / B .DataFrame)
数据结构存储全部数据会比较高效。
② 全部数据保存于变量df 中,为筛选出订单日期为2021 年第一季度内的所有记录,
可以执行Python 语句df1 = ,则df1 中保存筛选结果。(单选,填字母。
提示:多条件筛选时,条件之间用“&”连接,表示需要同时满足这多个条件)
A.df[ (df['订单日期'] <= '2021-1-1' ) & (df ['订单日期'] <= '2021-3-31') ]
B.df [ (df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] >= '2021-3-31') ]
C.df [(df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] <= '2021-3-31')]
-
(3) 经过以上两步处理之后,为了解“所在地市”第一季度“订购数量”前10 名的情况,
编写如下Python 程序段:
#数据整理结果保存于变量df1中,代码略
g = df1.groupby('所在地市', as_index = False).sum()
print )

则划线处的代码可为( )(多选,填字母)
A . g.sort_values('订购数量',ascending = False) [0:10] B . g.sort_values('订购数量',ascending = True).tail(10) C . g.sort_values('订购数量',ascending = True)[0:10] D . g.sort_values('订购数量',ascending = False).head(10) -
(4) 根据以上数据整理结果,小明对第一季度所在地市的“订购数量”进行可视化处理,如图b所示。
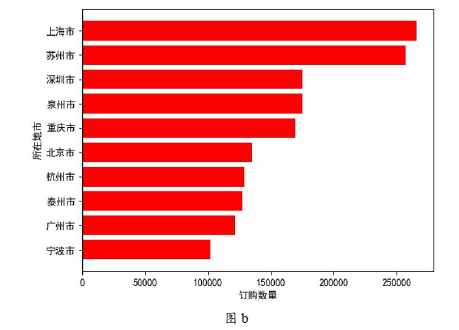
实现上述功能的Python程序部分代码如下:
#按“所在地市”对第一季度数据分组并求和,再按“订购数量”升序排序
#选取最后10条数据,存入变量s,代码略
import matplotlib.pyplot as plt
x = s['所在地市']
y =
plt.barh(x, y, color = 'r')
plt.show( )
程序中划线处代码应为。
-
(5) 小明借助大数据技术,对近几年来该网络购物平台的日用化妆品销售数据进行了分析。
应用该分析结果可能提供的数据服务是(列举一条即可)。
- 已知曲线y=,则y′=______________.
- 进行“验证机械能守恒定律”的实验:(1)现有以下器材:带铁夹的铁架台,打点计时器以及复写纸、纸带,导线,还需要的器材是_
- 运用下列任意4个成语,写一段内容健康、主题明确的话。(60字以内)问心无愧 白驹国隙 郑重其事 梦寐以求 孜孜不倦 开卷
- 有位同学用小球做“性状分离比的模拟”实验。该同学每次分别从Ⅰ、Ⅱ小桶中随机抓取一个小球并记录字母组合。将抓取的小球分别放
- 下列饮食习惯符合平衡膳食基本要求的是( )A.多吃煎、炸食物 B.不吃青菜
- 酸奶的制作与下列哪种生物有关( ) A.酵母菌 B.乳酸菌
- 如图,平行四边形ABCD中,AE⊥BC,AF⊥DC,AB∶AD=2∶3,∠BAD=2∠ABC,则CF∶FD的结果为
- 打破了世界各地区间的封闭和孤立状态,把旧大陆和新大陆联系在一起,世界历史迈出了从分散走向整体的关键性一步指的是( )
- 已知数列{an}满足a1=0,an+1= (n∈N*),则a2010=________.
- 在“靖康之变”中被掳走的北宋皇帝是()A.宋太祖 、宋太宗 B.宋太宗、宋徽宗C.宋徽宗、宋钦
- 在二氧化锰的催化作用下,过氧化氢迅速分解生成氧气和水.哪些因素还影响着过氧化氢分解的速率?课外活动小组结些进行了更深入的
- She hesitated _______ before she made up his mind. A. for in
- 心脏的四个腔的心壁肌肉最厚的是 ( ) A 右心房 B 左心房
- 英国发动鸦片战争的主要意图是: A.保护鸦片贸易 B.割占中国领土 C.打开中国商品市场 D.争取外交礼仪平等
- (本题16分) (1)用红、黄、蓝、白四种不同颜色的鲜花布置如图一所示的花圃,要求同一区域上用同一种颜色鲜花,相邻区域用
- 已知点P(2,0)及⊙C:x2+y2-6x+4y+4=0.(1)当直线l过点P且与圆心C的距离为1时,求直线l的方程;(
- ......
- 下列有关化妆品的选择使用不合适的是( ) A.干性皮肤应使用碱性强的护肤品 B.中性皮肤秋冬季
- 一辆汽车由甲地出发向乙地做匀速直线运动,途中司机下车办事,汽车停了一段时间后继续做匀速直线运动,最后到达乙地。下图所示的
- (共7分)依据氧化还原反应:2Ag+(aq) + Cu(s) = Cu2+(aq) + 2Ag(s)设计的原电池如图所示



